
Funktionen
VLM/OCR-Pipeline
Kombiniert Vision Language Models mit klassischer OCR-Technologie, um Text aus Dokumenten, Scans und Fotos zuverlässig zu extrahieren.
Human-in-the-Loop
Nutzende bestätigen oder korrigieren vorgeschlagene Feldwerte vor der Übernahme. Keine automatische Befüllung ohne Prüfung.
Strukturierte Datenextraktion
Extrahierte Informationen werden als strukturierter JSON-Datensatz aufbereitet und können direkt in Fachverfahren übernommen werden.
Dokument-Upload
Unterstützt gängige Formate wie PDF, JPEG und PNG. Dokumente werden sicher verarbeitet und nicht dauerhaft gespeichert.
Vorschau & Zuordnung
Extrahierte Werte werden den zugehörigen Formularfeldern zugeordnet und visuell hervorgehoben – für transparente Nachvollziehbarkeit.
Entity Graph
Unser Entity Graph überführt statische PDF-Formulare in ein strukturiertes Datenmodell aus Entitäten, Attributen und Relationen. Das ermöglicht Validierung, Kontextlogik und KI-gestützte Verarbeitung auf semantischer Ebene statt reiner Feldabfrage.
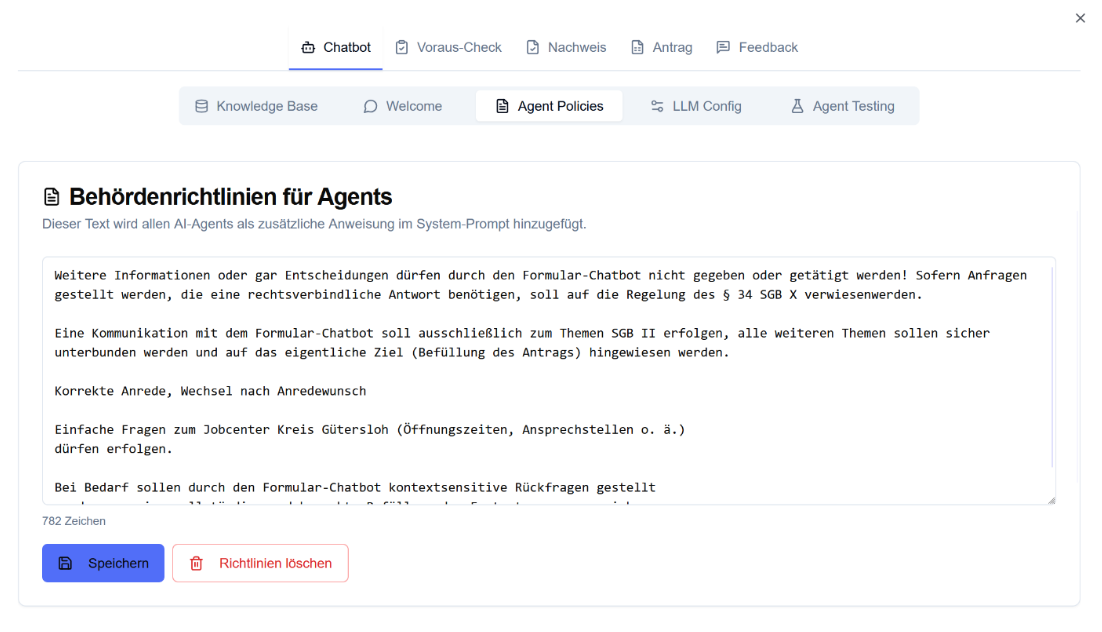
Admin-Panel
Inhalte, Dialoglogik und Behördenrichtlinien pflegen — ohne eine Zeile Code. Das Admin-Panel gibt Fachverantwortlichen die volle Kontrolle über alle Module.
- Knowledge Base, Welcome-Nachrichten & Agent Policies konfigurierbar
- LLM-Konfiguration und Agent Testing direkt im Browser
- Bis zu 5 Admin-Zugänge pro Instanz
- Multi-Modul-Verwaltung: Chatbot, Voraus-Check, Nachweis, Antrag, Feedback
Vorteile
Reduziert manuelle Dateneingabe und Übertragungsfehler
Beschleunigt die Antragserfassung bei vorliegenden Nachweisdokumenten
Gibt Nutzenden die volle Kontrolle durch Bestätigung jedes Feldes
Integrierbar in bestehende Formularstrecken via API
So funktioniert es
Dokument hochladen
Nutzende laden ein Nachweisdokument (z. B. Mietvertrag, Gehaltsabrechnung) direkt im Antrag hoch.
Extraktion & Zuordnung
Die VLM/OCR-Pipeline extrahiert relevante Daten und ordnet sie den passenden Formularfeldern zu.
Bestätigung & Übernahme
Nutzende prüfen die Vorschläge, bestätigen oder korrigieren sie – erst dann werden die Werte übernommen.